

Advancements in artificial intelligence (AI) technology constantly spark conversations around its implications on art: Can AI make art? Is it still art if it's made by an AI? What makes art, art? Why we make art? And is art what makes us human? What, if anything, distinguishes humans from machines? Is there a secret sauce to make human art that AI is missing?
To inform our outlook on the implications of AI on art, we need to take a close look at AI, art, and their intersections. In this article, we will look at AI, and turn to other pieces of the puzzle in subsequent articles.
Table of contents
How Does AI Work and What Can It Do?
You might already have an impression about AI based on your interactions with Alexa or ChatGPT; perhaps they are impressive but not really up to the mark? You might wonder how companies like Google, Netflix, and Meta use AI to improve their services, or you might be apprehensive about all the data they collect from their users and to what end they use it. And above all, you might think AI is some magical black box that somehow understands and does the job, sometimes exceeding our expectations, sometimes failing terribly.
To avoid undue exaggeration or underestimation of AI's capabilities, it is worthwhile to know exactly what AI is, how it works, and what it can accomplish. Let us look at the inner workings of AI models (but without coding or mathematics) to demystify AI. This will inform our discussion later in the context of art.
Why AI
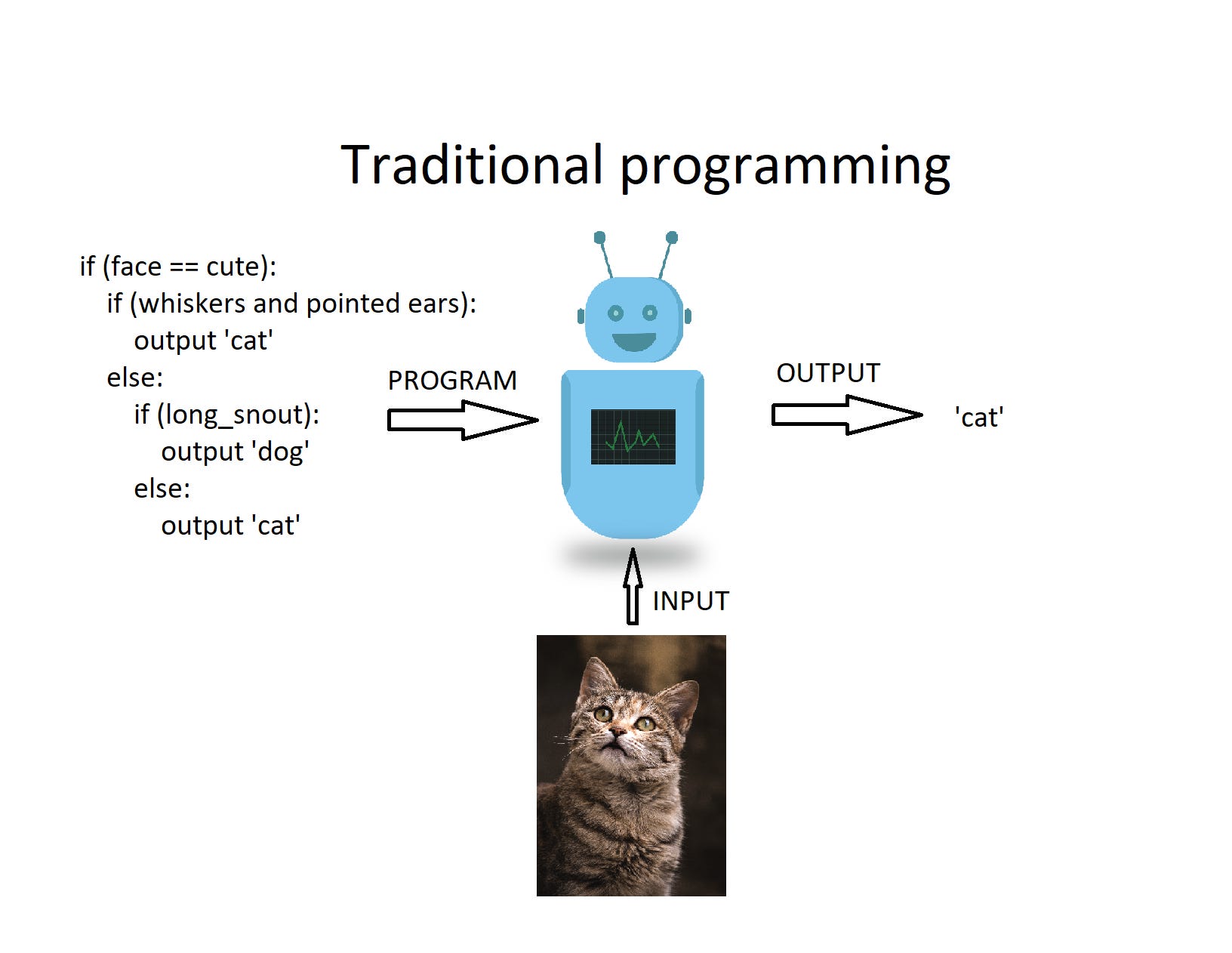
Unlike traditional computer programs that follow explicit instructions to execute tasks, AI can learn patterns and make decisions based on data. AI can, for example, estimate the price of a house by analysing numerous factors (features such as the size and age of the house, its location, real-time real-estate indicators, and many more) without being told explicitly how the price depends on these factors.
We need AI to solve such problems because real-estate prices may depend on numerous factors and in complex ways, so it may not be possible to just calculate its price using a static formula or a straightforward if-else algorithm. We first need data about prices and other features of a lot of houses. Using these data, an AI model can learn how price depends on these features and then predict the prices of other houses that are not in the original data.
Machines that learn
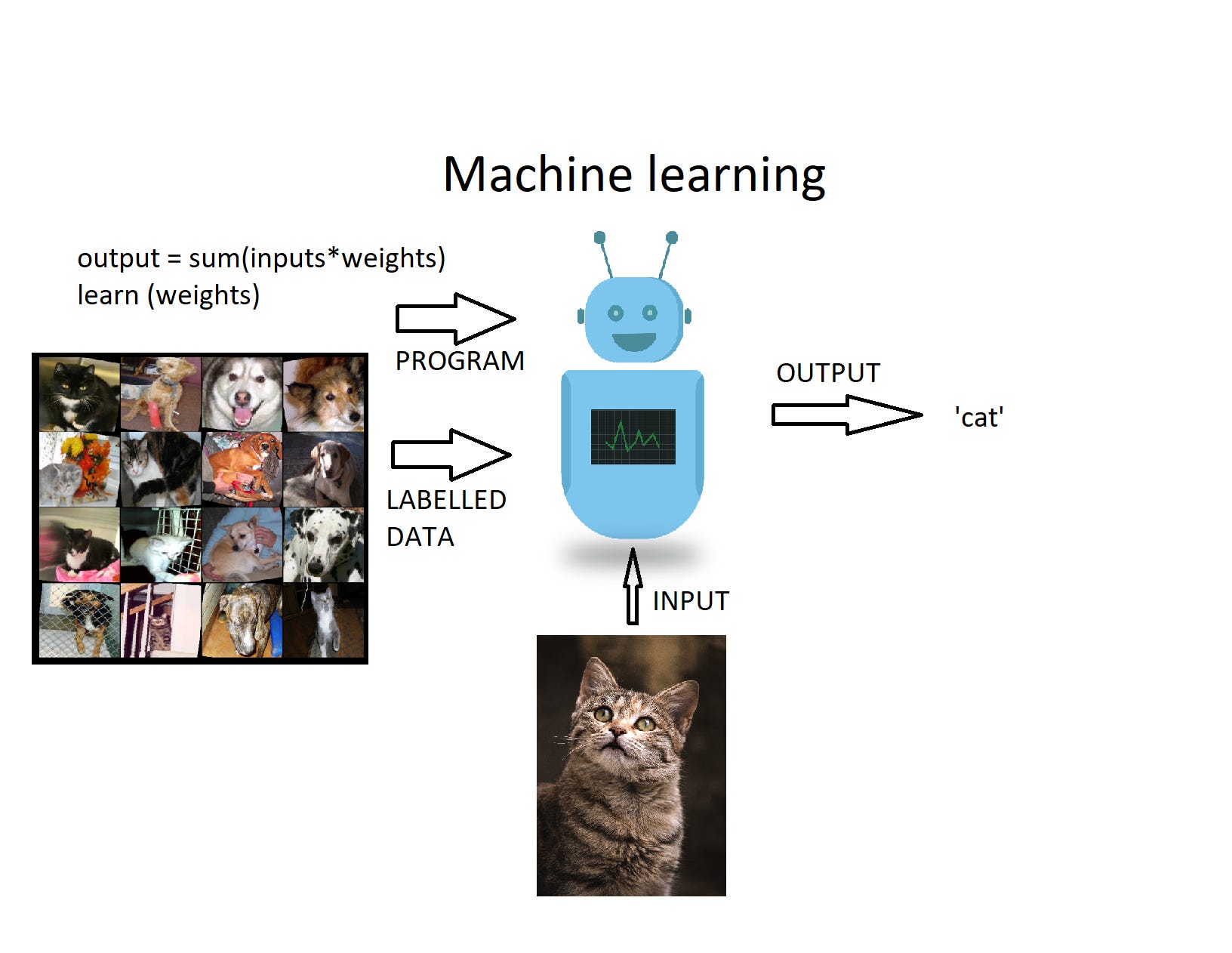
Machine learning (ML) is one of the main subsets of current AI approaches. In our example, 'learning' simply refers to finding out the formula to predict house prices by looking at data of other houses. In a simple scenario, we start by assuming a linear relationship between the inputs (house features) and the output (price of the house), and we model this relationship as a simple linear combination of input values, i.e., a weighted average of the inputs. This is good enough to learn a linear relationship between house features and prices. But we need to know the right values of the weights to get the right output. We need to learn the weights.
To do this, we first initialise the weights to arbitrary values. Now we present the model with sample features from our training data (i.e., data that contains house features and house prices) and see how close its output is to actual prices of our sample houses. We then adjust the weights just slightly to see if the output comes any closer to the actual prices. We repeat this several times, sometimes thousands of times or more, to get the right values of the weights that satisfactorily approximate the linear relationship between house features and prices.
Once the model is trained this way, we can now use it to predict prices of other houses. This is known as linear regression. The machine has somehow learned how house prices depend on its features.
Basic ML tasks and tools
The kinds of basic functions that ML models can perform are fairly simple and limited: regression (predicting a continuous value from a given set of features; e.g., predicting the price of a house based on its features), classification (identifying which of the two or more categories a given example belongs to; e.g., identifying whether a picture is of a cat or not of a cat), clustering (grouping similar items together without info on how they are similar; e.g., identifying market segments), etc.
Although they seem like simple tasks, their applications are very powerful. Regression can be used to predict stock prices, credit scores, grades of a student, and medical prognosis of a patient; classification for image recognition, spam filtering, sentiment analysis, voice/face recognition, and medical diagnosis; and clustering for social network analysis, market analysis, and genomic data analysis.
Apart from the linear regression method we saw earlier, there are many other ways in which a model can learn from given data. These include logistic regression, decision trees, random forests, support vector machines, KNN classifiers, naïve Bayes classifiers, collaborative and content-based filtering, polynomial regression, time-series regression, and many more. There are many ways in which machines can be taught to perform these basic ML tasks, and we’ve seen one of them (linear regression) in some detail. Moreover, there are several non-ML approaches to AI, which use substantially different techniques to make machines ‘intelligent’.
AI is a tool, not a magic wand
AI is not a one-size-fits-all solution that can magically solve all problems. Instead, AI is a toolbox that helps us solve specific problems in specific ways. We need to choose the right tool for any given problem. For this, we need an understanding of how different AI tools work, their scope of application, and their limitations. For example, some regression models perform well with linear data, some with periodic data, some with noisy data.
The performance of different clustering algorithms is compared below. Six different datasets with varying structures among data are presented to different models such as KMeans, affinity propagation, and DBSCAN. The clusters identified by the models are indicated with colours. For example, the MeanShift method (third column) identifies 3 clusters (orange, green, blue) in the first dataset (two concentric circles; first row), whereas DBSCAN (seventh column) identifies two clusters in the same dataset. The takeaway here is that, depending on the structure of our data, we may need to employ different tools to achieve efficient clustering.

In addition to selecting or developing the right tool, we also need to choose carefully what data we want to use. A machine learning model can't directly see, hear, or sense input examples. We must instead depend on a representation of the data to provide the model with a useful vantage point into the data's key qualities. That is, in order to train a model, we must choose the set of features that best represent the data. This often requires domain knowledge and effective framing of the problem. For example, if we are working with music, we need to define what exactly constitutes ‘data’ in our study: audio files, spectral properties of audio, metadata, symbolic scores, etc.
Neural networks and deep learning
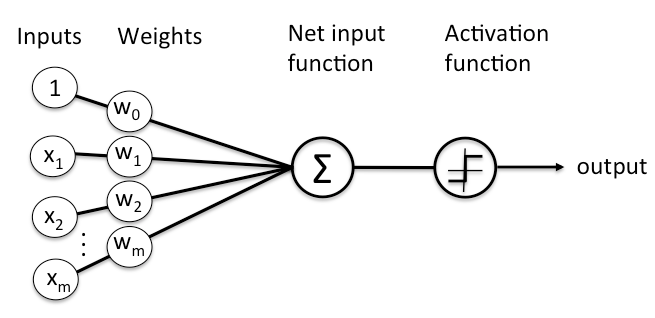
A neural network is a scaled and more complex tool that takes these tasks to the next level. They are called so because they are a layered network of 'neurons' or nodes, where each node is a computational unit that receives one or more inputs, processes them (e.g., takes a weighted average), and gives an output, effectively performing the equivalent of a regression (pictured above). Nodes are called neurons because they are inspired by the structure and function of biological neurons in the brain.
Neural networks can handle more complex relationships and non-linearities within the data, learn hierarchical and intricate features, and automatically extract patterns that might be challenging for traditional models.
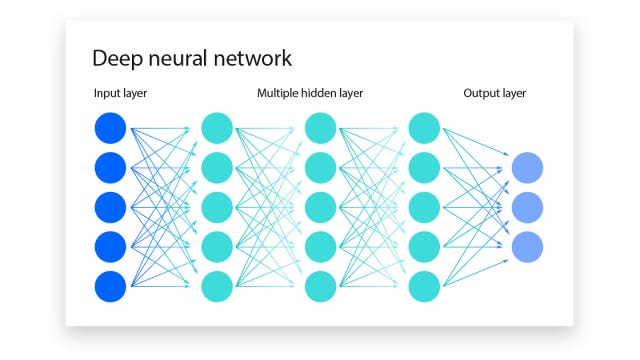

The layers in a (deep) neural network contribute to capturing high-level features through a hierarchical and compositional representation of data. Each layer learns and extracts features at different levels of abstraction.
For example, in image processing, the initial layers in a convolutional neural network (CNN; a type of neural network) learn low-level features like edges, textures, and colors. As you go deeper into the network, intermediate layers may capture more complex shapes, patterns, or object parts. The final layers can learn high-level features like object shapes, structures, or even semantic information; the last layers may represent the presence of specific objects or scenes.
Similarly, in financial data, initial layers may learn basic patterns such as price movements, volume changes, or short-term trends; intermediate layers may capture more complex patterns like trading patterns, correlations between financial instruments, or certain market conditions; and the final layers might extract high-level features related to market sentiments, economic indicators, or anomalies in the financial data.

Neural networks excel in capturing complex patterns and relationships in data, making them versatile for various tasks.
Deep learning takes the power of neural networks even further by introducing deep architectures with many layers of neurons. This depth enables the network to automatically learn hierarchical representations of data. Deep learning excels in tasks involving large datasets, complex patterns, and unstructured data, outperforming traditional models in various domains.
Applications of neural networks and deep learning include speech recognition, speech synthesis, natural language processing, complex language modeling, machine translation, image generation, computer vision, reinforcement learning (making dynamic decisions; e.g., in robotics), drug discovery, medical research, emotion recognition, and advanced recommendation systems (e.g., YouTube or Netflix recommenders).
Interpretability
In some cases, we can make sense of what the neural network is doing, like tracing the results of each layer to some level of abstraction as in the face recognition example. However, generally, deep learning models have low interpretability. They may be able to learn from the data, crunch the numbers and produce predictions, but this learning does not always provide us with insights into the data.
In some applications, we don’t care how or why a model generates a specific result; e.g., in character recognition, we usually don’t intend to ask questions such as ‘what makes the character ‘b’ different from the character ‘a’?’ We just want the system to accurately identify characters, no matter how it does that.
However, in some applications such as cancer diagnosis, we want to know why an AI model thinks a patient has cancer. Human experts (doctors, in this case) may want to check the results of this model before recommending a treatment plan. They may also want to understand what distinguishes positive diagnoses from negative ones. This helps not just in understanding cancer better, it also helps us trust the AI better when we can interpret its results in terms that we understand.
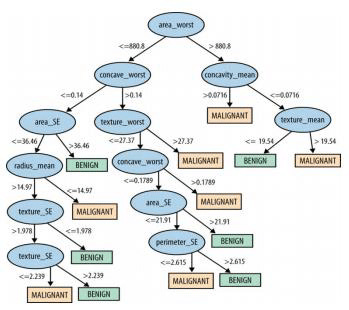
Some models inherently have better interpretability than others. Decision trees usually provide a more ‘transparent’ prediction mechanism than, say, neural networks. Usually, a high interpretability offers unique insights into the data. It may even help us see patterns in data that were so far unknown.
ML models are intelligent only within their scope
With such advanced machine learning abilities, it may look like AI can learn almost anything. This is true, in some sense. If we can frame the problem the right way, collect enough data, and choose the right training methods, we might be able to train AI on almost anything. However, this doesn’t mean that one model can solve all problems.
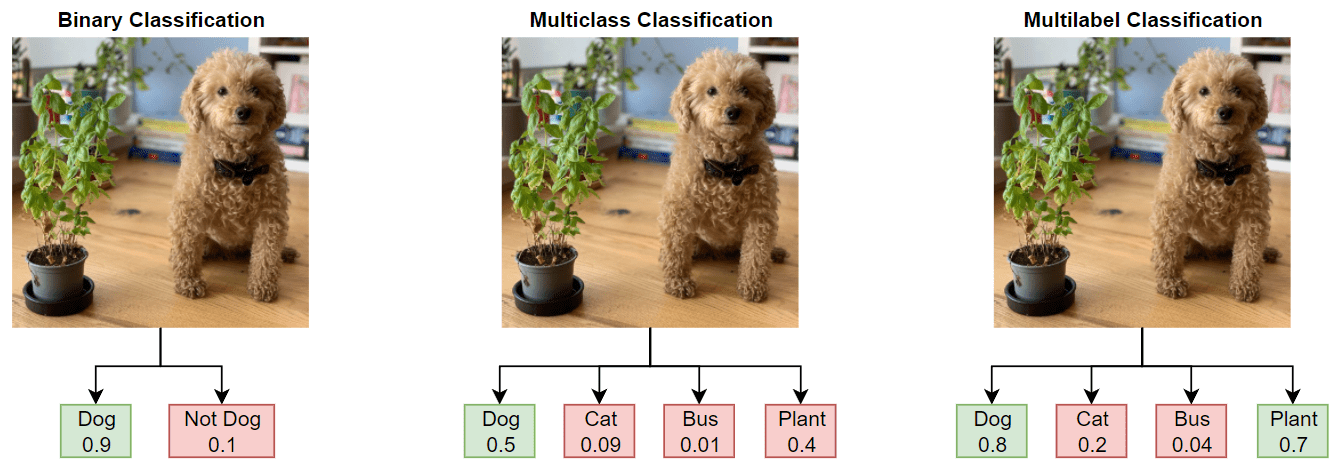
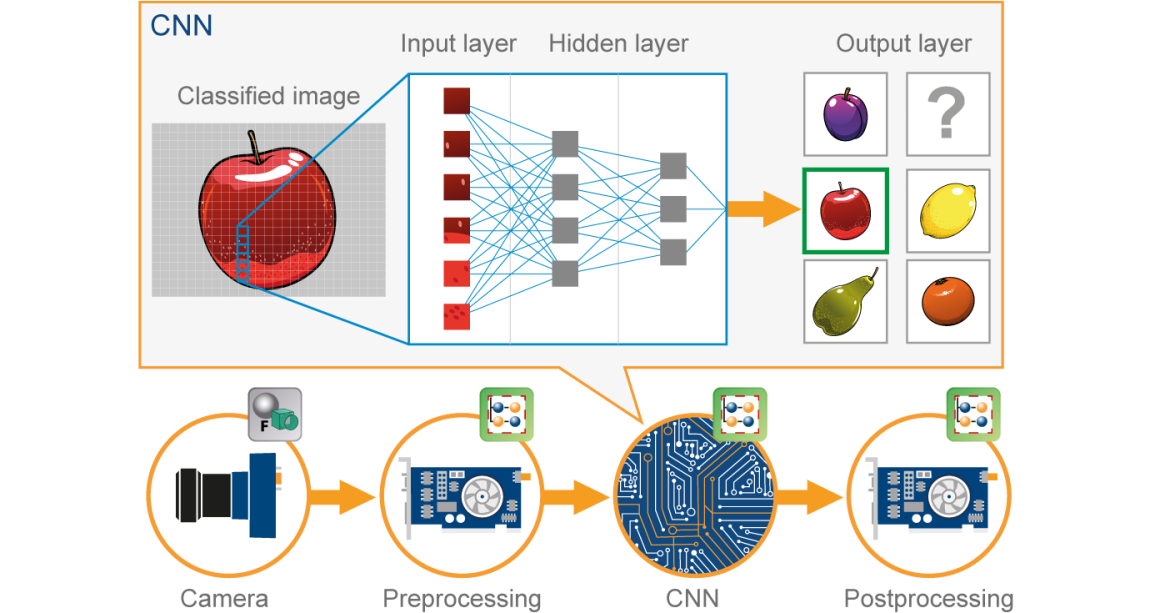
We need to specifically design and train models and learning methods that are tailored to specific problems. For example, in the image recognition task below, the AI model takes an image as input and returns probabilities as outputs. Depending on how we frame the classification problem, we get different outputs, hence making the model useful in different scenarios.
One more example of limited intelligence of these systems is character recognition. Although a CNN can excel at recognising hand-written digits, its output will always be a digit ranging from 0 to 9. Even if we input an image of a hand-written character ‘b’ or an image of a cat, the classifier still gives an output between 0 and 9, because that is what it has been designed to do.
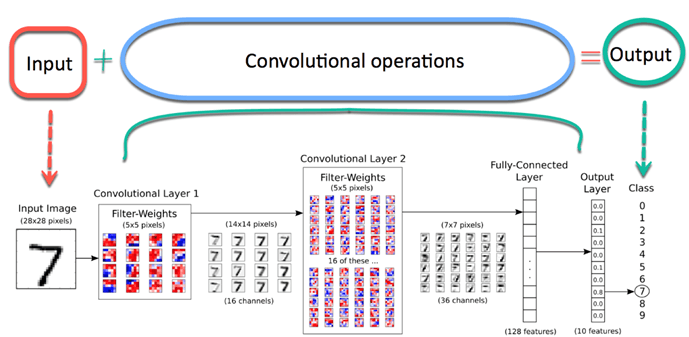
The ML pipeline
AI may not be magically intelligent in another aspect: we have to spoon feed the algorithms. For example, just presenting an image may not be sufficient for an image classifier. We have to preprocess the image so that it is matches the model’s expectations and requirements. For example, we may have to crop and zoom so that our object of interest can be identified, and adjust the contrast and brightness so that our model picks up on the features of this object. We may also need some postprocessing to make sense of the model’s outputs.
Thus, an ML model is usually part of a process, and not the entire process itself. We need a deeper understanding of our data, the pre- and postprocessing steps, and the requirements and working of the model.
ML models aren’t omniscient either. If there is not enough information to solve a problem, AI may be unable to work (at least, without assumptions). For example, if a model is trained to identify apples from cherries but we present it with a low-resolution image featuring a roundish red object at an ambiguous magnification, the model is effectively just guessing the output. Similarly, sometimes it may be impossible for humans to tell apart the handwritten letter b from the numeral 6 without context. We can’t expect an ML model to do any better in some cases.
ML needs data
All machine learning tasks rely on training data to learn and improve their accuracy over time. In the housing price prediction example, we need data about other houses. For image processing tasks, we need datasets of images; for music analysis, we need datasets of audio tracks, MIDI scores, or metadata; for speech recognition, we need audio recordings paired with transcriptions or phonetic annotations.
Other examples of data include historical stock price data, with features like opening price, closing price, volume, etc.; user-item interaction data, such as user ratings, clicks, or purchases; large datasets of diverse images for training a generative model; interaction data in an environment, often collected through simulations or real-world trials; and medical images with pixel-level annotations for segmentation tasks.
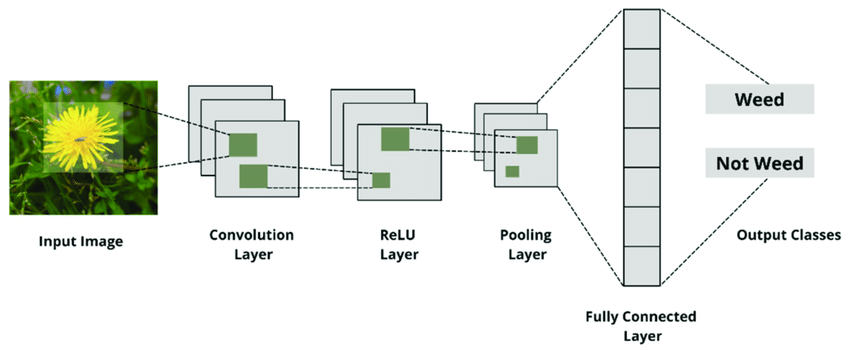
The results we get from an ML model depend on the quality of data. If our data are not reliable, diverse, complete, or accurate, our model may be compromised. For example, to train a model to detect weeds, we need enough representation of different weeds in varying lighting and backgrounds, along with representation of non-weeds that may look like weeds.
AI that truly fascinates
When we think of AI, we don’t usually think about these basic and mundane tasks such as estimating values and classifying items. In recent popular imagination, AI has been associated with complex innovations such as talking robots, self-driving cars, large-language models (such as ChatGPT) and music generation systems. And it may be hard to see how these complex tasks can be performed by a machine.
These complex problems are solved using combinations of the basic techniques we saw above. For example, a talking robot uses several models for speech recognition, natural language processing, and speech synthesis, with deep learning architectures enabling it to understand complex language structures, nuances, and variations, facilitating more sophisticated and human-like interactions.
Self-driving cars use image classification for recognizing and categorizing objects in the environment—pedestrians, other vehicles, traffic signs, etc. They use regression to predict the trajectory of objects in the car's environment, estimating their future positions, to avoid collisions. They use complex neural networks that can predict sequential data, helping in understanding the dynamic nature of the road environment. They also use deep learning for complex decision-making processes using data from its numerous sensors and make real-time decisions on steering, acceleration, and braking, with advanced techniques to fine-tune decision-making strategies based on the car's interactions with the environment.
Take-home message
To summarise, we have briefly looked at what AI is, what it can do, and how it does that. We have looked mostly at neural networks, but the insights hold for other AI approaches as well.
AI can perform tasks that were not possible using traditional programming methods.
AI models can learn from data using complicated mathematical methods.
The kinds of tasks that ML can perform are limited but powerful.
AI should be perceived as a toolbox and not as a magic wand.
Many a time, ML models lack interpretability.
To solve a problem using AI tools, we first need to frame the problem in a way that makes it amenable to AI methods.
Reliable and representative data are required to train ML models.
ML is just part of a process. Data collection and pre- and postprocessing are as important as ML.
Complex applications such as self-driving cars are accomplished by combinations of simpler tasks.
In the next article, we will look at art, before finally discussing the intersections of AI and art.